假如要用一个词语来形容我们认识这个世界的过程和结果,“盲人摸象”大概是比较合适的了。而要解释一个现象的成因、结果,或者要研究一番因果关系——当然在大数据年代,“相关性”分析更为流行——更是难上加难。受制于人的局限,也因于人的才智,抽样作为一种研究方法在历史上被发明了。它有着极其悠久的历史。或者说,文明之初,圣贤对世间种种问题的论断也是以此为基础,毕竟无法走遍天下穷尽对所有人和物的认识。人们希望通过样本去推断整体,在概率上实现一种“可能性”认识。在现代学术界,以学术为业的研究者穿梭于数据之间,为的也是得到一个比较可靠的推论。
他们苦苦盯着p值(指用来判定假设检验结果的参数),祈祷神奇的统计软件得出“p
电影《美丽心灵》(ABeautifulMind,2001)剧照。
不过,小概率事件就是不可能事件吗?好像也未必。或许样本的数据只是碰巧支持了研究假设,或许研究者调整了某个数据以求通过显著性检验。即便这些问题都不存在,当样本的数量不断扩大,直至扩至总体,有一个小概率事件发生了,显著性检验似乎也都面临着某种意义危机。
不妨举一个简单的例子来说明。我们假设“阅读的时间”和“刷短视频的时间”没有任何关系,在样本中发现没有任何关系的可能性低于0.05,也就是不足5%,那么也就通过了显著性假设,有95%以上的把握说阅读和刷短视频两者之间有关系。只要发现有一个人阅读和刷短视频互不干扰,小概率事件都算是发生了。既然小概率事件总是会发生,又怎样理解p值的意义呢?我们自然可以说,在实证意义上,它告诉我们具体有多大把握可以作某个推论。除此以外呢?统计学家奥布里·克莱顿做了一件有趣的事,他追溯统计学的历史,告诉了读者统计学上的谬误、危机和争议,包括让无数人“辗转反侧”的p值。
“对显著性检验——特别是零假设显著性检验——的批评有着特别悠久和丰富的历史。我将只讲述有关其中一些批评的故事,主要是试图理解为什么它从未成功地推翻现有规则。可悲的是,这主要是关于科学界普遍存在的冷漠和惰性的故事。”
以下内容经出版方授权节选自《伯努利谬误:不合逻辑的统计学与现代科学的危机》一书。摘编有删减,标题为摘编者所起。注释见原书。
原文作者|[美]奥布里·克莱顿

《伯努利谬误:不合逻辑的统计学与现代科学的危机》,[美]奥布里·克莱顿著,陈代云译,2024年2月。
当问题浮出水面
随着21世纪初至21世纪头十年中期科学研究的变化,显著性检验的理论问题开始变得非常实用。一方面,研究人员可用的数据量呈爆炸式增长。快速增长的数字存储容量以及共享数据或在线进行研究的能力使全新类型的数据分析成为可能。在那段时间,大数据、数据挖掘和机器学习成了家喻户晓的流行词。

纪录片《统计的乐趣》(TheJoyofStats,2010)画面。
约翰·霍普金斯大学生物统计学教授罗杰·彭通过比较斯坦利·米尔格拉姆1967年的六度分隔实验与其现代等效实验,总结了研究数据的可用性发生了多大的变化:
1967年,斯坦利·米尔格拉姆做了一个实验以确定美国两个人之间的分隔度。在他的实验中,他向内布拉斯加州的奥马哈和堪萨斯州的威奇托寄去了296封信,目标是把信寄给马萨诸塞州波士顿的某个特定的人。他的实验引入了“六度分隔”的概念。2007年的一项研究将这个数字更新为“七度分隔”——但最新的研究基于在30天内收集的300亿个即时通讯对话。
在这十年中,从金融到市场营销、精算学、通信、医疗保健、药理学等不同行业,试图在大量的数据集中找到有用的相关性的分析性研究突然兴起,特别是在医学领域。2003年人类基因组计划的完成为研究人员提供了一个广阔的新领域,在这个领域中,他们可以探索数百万个基因组对任何数量的疾病或其他疾病的潜在影响。
也就是在那个时候,这些研究人员开始注意到他们复制结果的能力存在问题。2003年发表在《柳叶刀》(Lancet)上的一篇调查文章中,海伦·科尔霍恩、保罗·麦凯格和乔治·戴维·史密斯发现了一个日益严重的问题,“即许多结果无法被复制,这就导致人们越来越怀疑简单关联研究设计在检测造成共同复杂性状的遗传变异方面的价值”。他们认为,尽管新的后基因组时代给他们带来了许多优势,但要探索的可能关系以及进行探索的人数的爆炸性增长导致了许多虚假关联被偶然发现:
我们认为,未能排除偶然性是复制复杂疾病基因关联报告的困难的最可能解释。对于大多数我们感兴趣的疾病而言,数百个已知基因是可能的候选基因,在大多数这些基因中,数十个多态性是已知的或者可以通过基因筛查被轻松识别。世界各地的科学家每周都会对数千种这样的多态性进行疾病关联检验。即使这些基因型都与结果无关,我们也可以预计,许多在5%或更低水平上显著相关的关联往往只是偶然发生的。
大多数研究结果都是错误的?
然而,第一个真正令人震惊的事件发生在2005年,当时斯坦福大学医学院及其统计学系的教授约翰·约安尼迪斯将复制问题归咎于正统的统计学方法,主要是NHST(即“零假设显著性检验”,NullHypothesisSignificanceTesting——摘编者注)。在一篇名为《为什么大多数已发表的研究结果都是错误的》(WhyMostPublishedResearchFindingsAreFalse)的文章中,他用一个简单的贝叶斯论证证明,如果一种关系,如基因与疾病发生之间的关联,其先验概率较低,那么即使它通过了统计显著性检验,其后验概率也可能较低。
例如,他考虑对精神分裂症的基因关联进行检验。

电影《飞越疯人院》(OneFlewOvertheCuckoo'sNest,1975)剧照。
关于这种疾病遗传性的先验经验可能表明,在10万种可能的基因变异中,大约有10种可能确实在一定程度上与精神分裂症有关。因此,分配给任何一个可能理论的先验概率应该是10/100000,或0.0001。一个典型的检验将使用5%的显著性水平,对于这种规模的效应,可能有60%的功效来发现结果,这意味着即使效应是真的,也只有60%的几率获得显著的结果。将这些数字放入推断表的结果如下表所示。这种效应的后验概率约为0.12%,这意味着即使对一个不太可能的遗传关联的推断给出了统计上显著的结果,也有99.88%的概率表明这种关联是不真实的。
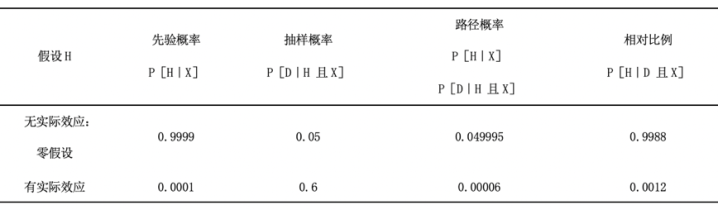
给定一个有统计显著性的结果,对不太可能的基因关联的推断。
一般来说,假设任何理论的先验概率为p,并将假设的假阳性率(α)和假设的假阴性率(β)放在一个推断表中,我们将得到如下表所示的结果。观察结果D表示“观察到的效应具有统计显著性”。
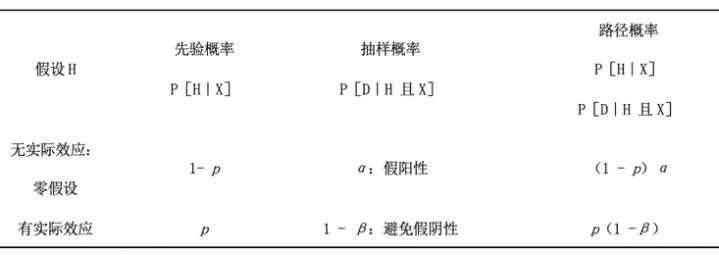
给定有统计显著性的结果,一般推断。
因此,如果第二个路径的可能性小于第一个,那么通过显著性检验的效应的真实概率将小于50%。就上面表格中的数量而言,如果p(1-p)
因为在大多数显著性检验中,α通常被认为是5%以及一个典型的检验可能有50%左右的假阴性率,如果真对假的失验比例低于10%,这意味着大多数已发表的研究结果将是假的。鉴于在这项“高通量发现导向的研究”中研究了大量可能的影响,约安尼迪斯说,任何给定理论的先验概率都会远远低于这个阈值,这是常态。他进一步表明,由选择性报告或研究人员利益冲突导致的偏差的影响会使这种低后验概率变得更低。
因此,大多数已发表的研究结果都是假的。
或者都是真的?

电影《唐伯虎点秋香》(1993)剧照。
“我们拒绝零假设是正确的!”
在对基因关联研究的分析中,约安尼迪斯本质上认为,我们应该预料到第一类错误发生的百分比很高,该错误是指拒绝一个零假设(没有影响),即使它为真。他的计算结果显示,第一类错误率(也就是在零假设成立的情况下得到统计显著性结果的概率)与已发表结果中属于第一类错误的真实百分比之间存在明显差异。用符号表示是P[显著性|H0]与P[H0|显著性]的区别。后者反映了给定数据下的零假设的概率,这需要进行贝叶斯分析,包括借助假设的先验概率来理解。这与某种疾病的检测结果呈阳性的健康患者的百分比和检测结果呈阳性但实际上是健康患者的百分比之间的差别是一样的。为了计算真正想要的概率,我们需要包括基础概率,即先验概率。

电影《美丽心灵》(ABeautifulMind,2001)剧照。
约安尼迪斯通过考察一种理想化的情况进行了示例计算,在这种情况下,人们可以研究的所有可能的基因关联都被分成两类:一类是真实的关联,对疾病的发病率有一定程度的影响,另一类不是真实的关联,其影响为0。这使得推断类似于我们的忽视基础概率问题,在忽视基础概率问题中,患病等条件要么存在要么不存在。
然而,对于许多类型的问题,有更多的可能性。
在任何两个变量之间,可能会有微小的关联,它们仍然是真实的,但在任何层面上都没有实际意义。
例如,用费雪的方法来思考一个关于总体的推断,如果考虑到整个总体,任何给定的一对变量之间都不太可能有精确的0关联。比如,我们研究了美国政治党派和家庭收入之间的关系,我们有兴趣拒绝零假设,即拒绝认为这些变量是独立的,也就是说,不同收入阶层的人口比例并不会因他们的政治立场而改变。如果我们能够调查每个人,我们几乎肯定会发现比例是不完全相等的,因为任何收入阶层中哪怕有一个人有差距都会破坏这个等式。由于这类调查问题中唯一的随机性来自抽样过程,我们可以近乎肯定地说,如果我们的样本容量足够大,我们会发现一些统计上显著的效应,我们拒绝零假设是正确的!
伯克森早在1938年就提出了这个问题的理论。他说,这对统计学家来说应该是真正的麻烦,因为这意味着基于样本拒绝零假设在原则上是没有意义的:“我想,统计学家会同意,大样本总是比小样本好。那么,如果我们事先知道从大样本中得出的p值,那么在小样本中这样做似乎是没有用的。但是,由于前一次检验的结果是已知的,所以这根本就不是检验。”
换句话说,如果在理想情况下,我们能够接触到整个总体,收集数据样本的目的是引导我们得出结论。但在不做任何研究的情况下,我们从一开始就知道某些类型的零假设在被应用到整个总体时几乎肯定是错误的。那么取样的意义是什么呢?
1966年,巴坎描述了同样的现象,并通过对从6万人中收集的数据进行统计检验,从实证上证明了这一点。
他表明,无论他如何划分他的受试者——密西西比河以东与以西、北部与南部、缅因州与美国其他地区等——这两组受试者之间的差异检验结果总是非常显著,p值很小。1968年,明尼苏达大学的戴维·莱肯将此称为“环境噪音水平(即很弱,可以忽略不计)的相关性”。他和米尔通过对57000份由明尼苏达州高中生填写的问卷进行分析来证明这一点。这项调查的内容包括学生的家庭、休闲活动、对学校的态度、课外组织等。他们发现,在105个可能的变量交叉表格中,每一个单独的关联都具有统计显著性,其中101个(96%)的p值小于0.000001。例如,出生顺序(老大、老幺、老二、独生子女)与宗教观点、家庭对大学的态度、对烹饪的兴趣、参加农场青年俱乐部的资格、离开学校后的职业计划等都有显著关联。米尔称之为“CRUD因素”,意思是“在心理学和社会学中,一切事物都相互关联”。

电影《双子的天空》(TwinFallsIdaho,2000)剧照。
但正如米尔所强调的,这些结果并非纯粹是偶然获得的:“我重申,这些关系不是第一类错误。它们是关于世界的事实,当N=57000时,它们相当稳定。有些从理论上很容易解释,有些比较难,有些则完全让人困惑。‘简单’的问题有时会有相互矛盾的多种解释,但通常不会。从一个(罐子)中提取理论,然后异想天开地将它们与变量对联系起来,将产生一批令人印象深刻的反驳H0的‘证据’。”也就是说,根据标准实践,这105项发现中的任何一项都可以被包装成一种理论,并发表在期刊上。
零假设总是会失败
随着更容易收集到更大的样本,人们可以预期这类小效应的结果越来越多。例如,2013年一项针对1.9万多名参与者的研究表明,与面对面认识的人相比,在网上认识配偶的人报告的婚姻满意度往往更高,其p值很小,仅为0.001。这听起来像是一个令人印象深刻的、非常热门的结果,直到你看到观察到的差异非常小:在这个7分制框架下,平均“幸福得分”为5.64对5.48,相对提升不到3%。
样本量和统计显著性之间的关系在早期是一个经常被混淆和批评的问题,直到今天也是如此。巴坎描述了20世纪60年代的期刊编辑在判断研究论文的质量时经常混淆的情况:
作者知道一些非常著名的心理学期刊的编辑以没有足够的观察为由,拒绝了p值和n值较小的论文,这清楚地表明,相同的思维模式在这些期刊中发挥作用。事实上,用一个小的n来拒绝零假设表明总体与零假设有很大的偏差,显著性检验的数学过程已经考虑到小样本的情况。增加n会增加拒绝零假设的概率;在这些因样本小而被拒绝的研究中,这项任务已经完成。当然,从某种意义上说,这些编辑是这个行业的终极“教师”,他们一直在教授一些明显错误的东西!
纪录片《数学的故事》(TheStoryofMaths,2008)画面。
也就是说,低p值似乎是件好事,而大样本容量也似乎是件好事,所以非常重要的是,结果应该包含这两种情况。但这必然意味着,声称的效应规模可能很小,因为如果不是这样,它就不需要在给定的显著性水平上用这么大的样本来发现它。因此,无论统计分析最初打算支持什么理论,都可能毫无意义。
如果可发表的研究的把关人只关心那些拒绝零假设、具有高功效、低假阳性率的研究,那么使研究得以发表的一个简单程序就是总是拒绝零假设!因为零假设总是假的,你可以声称你永远不会犯第一类错误(拒绝零假设,即使它是真的),而且你因为总是拒绝零假设,也不会有犯第二类错误(接受零假设,即使它是假的)的机会。
所有这些困惑都强调了一点,即如果没有可供检验的备择假设,假设检验是毫无意义的。当假设某一总体相关性正好为0或某一总体比例正好为1/2,用它的简单否定(即相关性不是0或比例不是1/2)来检验该假设时,如果数据量足够大,零假设总是会失败。但这并不奇怪,因为这些假设的先验概率基本上都是0。相反,我们需要给零假设一个战斗的机会,通过陈述使它们的先验概率不为0,或者更好的是,在一个连续统上处理假设,并分配先验和后验概率分布。
是科学还是只是噪音?
然而,真正的问题是,仅仅是结果具有统计显著性这一事实,根本不包含关于效应大小的内容。有了足够大的样本量,任何微小的效应(几乎总有一些)都是可以被检测到的,但这不能被视为对任何解释该效应存在的理论的验证。
正如心理学家埃德温·博林在1919年首次阐明的,这是一个科学假设,但它绝不仅仅是一个统计假设,即总体中的两个统计数据彼此不同,两个变量相互关联,一种处理有一些非零效应,同时它也试图解释原因、程度,以及重要性。忘记这一点是斯蒂芬·齐利亚克和戴尔德丽·麦克洛斯基在《统计显著性崇拜》(TheCultofStatisticalSignificance,2008)中所说的第三类错误。正如他们所说,“统计显著性并不是一项科学检验。这是一个哲学的、定性的检验。它没有问程度,而是问‘是否’。是否存在等问题,确实有意思。但这并不科学”。

纪录片《统计的乐趣》(TheJoyofStats,2010)画面。
此外,统计显著性最多只能解决一种可能困扰实验的误差,即抽样误差。在大样本实验中出现的奇怪的相关性表明,其他类型的系统误差,如选择性偏差或混杂变量的存在,也经常在起作用。理解和控制这些因素需要更仔细的思考,而不仅仅像在机械过程中转动手柄那样肤浅。
因此,大约从1930年至今,仅根据统计显著性来判断研究成果是否有发表价值的普遍做法,造成了两种不良科学研究被收录进文献的可能性。一个是简单的第一类错误,尽管不存在真正的影响,但通过侥幸成功的随机抽样,获得的数据通过了一个显著性阈值;根据约安尼迪斯的可怕预测,当研究人员筛选许多可能的关联,直到找到一个有效的关联时,这种情况可能会更常见。另一种可能性是第三类错误,即效应在统计学意义上为真,但实际上并不支持它应该支持的科学理论——也许是因为样本太大,程序发现了一个几乎没有科学价值的微小效应。可能是另一个因素,即研究人员没有想到的特定实验,可以在某种程度上解释这一发现,使其对其他人没有实际用途。1966年,在明尼苏达州的高中里,当被问及某一特定问题时,兄弟姐妹对大学的感觉可能真的不同,但只有当研究结果适用于某一特定的时间和地点之外时,它才有科学意义。
一种找出这两类错误的方法是看检验结果是否可复制,这种方法在21世纪头十年中期开始变得更加流行。如果某项研究声称的效应是真实的,即实际达到了该研究声称的程度,而不仅仅是在偶然达到显著性阈值之前尝试假设的结果,那么高强度的重复实验可能会再次发现它。如果一个小的影响实际上支持某些科学理论,而不仅仅是特定总体的结果,或是研究人员未能解释的某些无法解释的系统性偏差的产物,那么其他人在其他地方对其他实验对象进行的研究也可能会发现它。
长期以来,复制一直是科学真理的基石,也是科学方法的一个组成部分。所以问题的本质是,所有这些新的统计结果是科学还是只是噪音?
2005年,约安尼迪斯回顾了在1990年到2003年间进行的49项医学研究,其中45项研究声称一种疗法是有效的。总的来说,这些研究在研究文献中被引用超过1000次。他发现45项研究中有7项(16%)被后续研究反驳,这意味着没有发现显著的效应;另外7项研究声称比后续研究发现的效应更强;其中20项(44%)基本上被复制;其余的基本上没有受到挑战。这是一些令人不安的证据,但问题仍然可能局限于这类研究,正如他所预测的那样,这些研究的特点是有许多可能的关联需要考虑。
注:本文内容经出版方授权节选自《伯努利谬误:不合逻辑的统计学与现代科学的危机》一书。
原文作者/[美]奥布里·克莱顿
摘编/罗东
导语部分校对/刘军